
This is my 10th TSQLTuesday, andthis month Deepthi Goguri has given the double prompt to talk about our new favourite features in SQL Server 2022 and our New Year’s resolutions.
Now, for various reasons, I’ve not been posting on this blog for a while. Like, a long while. Like the last post was TSQLTuesday #138. I was going to do a post about why that was, but I haven’t got it written yet and I really want to post on this topic so that might come next week.
Anyway, the same things that kept me away from the blog (and a lot of other things) also stopped me from looking into SQL Server 2022 in any great detail. I did a post in April 2021 about the GREATEST and LEAST functions that were present in Azure and were coming to on prem at some point in the future, but apart from that I haven’t really been paying attention. With all of that, I guess the thing I’m looking forward to the most is the thing I don’t know is there yet. It’s always fun to watch talks and read blogs on new features, and think about how you can apply them to the big issues at your workplace and make life easier, so that’s what I’m hoping I’ll get a chance to do over the next few months.
New Year’s goals
Many years ago I stumbled on Brent Ozar’s epic life quest. Reading around that led me to Steve Kamb’s Epic Quest of Awesome, and I decided I wanted to do something similar. I write about this in more detail here, and list all of my goals here, but the basic idea is to make a list of things you want to do in your life, then focus on ticking them off. I really struggle with keeping focus on things for a long period of time, so having something like this allows me to take some time and set down what’s important, and refer back to it later as a guide to what I should be working on.
Some years after I did this I decided I was done with the idea of New Year’s Resolutions, because they always end up being a bit vague, and you get to the end of the year and you can’t really say if you did them, and they just tend to fade from my attention after a bit. I decided that what I wanted to do instead was set myself some concrete, S.M.A.R.T. goals, and to do that I largely pulled from my epic quest, along with a few other things. The last couple of years have been really bad when it came to achieving anything, because of the pandemic and other reasons, but this year I’m feeling a lot better, and I have some catching up to do, so I’ve been ambitious and set myself quite a few goals. The plan is to check in every 3 months and see how I’m doing, and keep all of them in mind as I go through the year. So, goals for 2023 are:
- Weigh under 95kg every day for 3 months. This has been something I’ve tried for a couple of years before now, but I think I’m in a better place to tackle it this year. The idea is if I can get to that weight and maintain it for 3 months it will set some healthier habits in place rather than immediately putting it all back on again.
- Deadlift 200kg. Current tested max is 165kg, but I think I’d be closer to 180kg if I tested it today.
- Deadlift 250kg. This is definitely more ambitious, and probably won’t happen until near the end of the year if at all.
- I’ve entered a novice strongman comp that’s coming up in about a month, so I’ve set myself the challenge of completing every event. That means getting at least one rep on the ‘for reps’ events, hitting all of the weights in the ‘progressive’ events (things like deadlift x weight then y then z, I want to get all the way to z), and completing the carry and pull medley in the time (carry 2 sandbags then pull a sled a set distance in 60 seconds).
- Finish a half marathon. I’ve not done much running the last couple of years, but I’ve entered the Nottingham half, which is the end of September, and if I train right I can definitely complete it.
- Paint a Warhammer 40k combat patrol. This was nearly completed last year, but I didn’t quite make it so I want to finish it off this year.
- Paint a Warhammer 40k incursion force. This will incorporate the combat patrol, but double the size of it. I really enjoy painting these models, so this is about having fun and reducing my ‘to be painted’ pile.
- Paint a gang/team/squad/something else for one of the Games Workshop boxed games. Same as above, painting relaxes me and gives me a feeling of achieving something.
- Related to painting, I had an idea for a simple app to track all the paints I currently own, and what paints I used on each model, to help me repeat existing paint jobs on similar models in the future. I’ve not done app development before, or really anything outside of databases, so I’m thinking I’ll set myself the challenge of building this in Azure, and hopefully learn some stuff along the way.
- Blog every week for 6 months. This blog is really neglected and I need to show it some love.
- Speak at another SQL Server user group. I spoke at the Nottingham user group a couple of times, and was just starting to get accepted to conferences when things got difficult. I’d like to do more speaking, and both the Cardiff and Bristol groups aren’t that far from me so I’m keeping an eye out for when they start up again this year.
- Sort out a group tent for larp. If you don’t know what larp is, this won’t make a lot of sense, but essentially I want to get a tent and decorate it like it’s from a magical fantasy kingdom.
- Book another big holiday. I may not get to go on one this year but I’d like to at least have one lined up for 2024 by the end of the year. I went to Bali over New Year and it was really good for me, and I feel like I need to do those trips more often.
- Have 5 smaller adventures this year. So far I’ve booked a running festival in the summer, and a new larp event, so I need to find another 3. I’m thinking some weekends in London to catch some shows.
Anyway, that is it (apart from one goal I’m keeping secret for personal reasons, but I’ll post if it happens). Like I said, some are off my epic quest and others are just things I thought would be good for me this year, but having the list to refer back to every time I have a spare half a day helps keep me focussed on chasing the things that matter more to me.
This is my 9th TSQLTuesday, and this month Andy Leonard has given the prompt “How Do You Respond When Technology Changes Underneath You?”
I’ve largely worked at places where we’ve used pretty stable products. Despite my best efforts, most of the teams I’ve been part of have been reluctant to adopt much in the way of cutting edge technologies. There are things I could write about like the change in SSIS from 2008 to 2012, and the associated relearning I had to do to keep myself current, but I think I want to talk about something a little different:
SQL Server version upgrades
I’m not 100% sure this is what Andy had in mind with his prompt, but it feels on topic enough that I’m going to go with it anyway.
SQL Server version upgrades are something most developers and DBAs will have to confront at one point or another, and I’ve found myself dealing with a few significant ones in the last few years. All have been from 2008R2, including the one my company is currently in the middle of (I wasn’t kidding when I said they don’t tend to adopt the most cutting edge technologies), and they’ve all gone a similar way. I’m not going into all of the details (one blog post is way too short to write a complete how to on this), but there are a few things I want to share about my experiences.
Data Migration Assistant
The SQL Server Data Migration Assistant is an amazing tool. You download it, point it at a SQL instance, tell it what database(s) you want to upgrade, and tell it the target version. It then tells you a lot of what you need to know in terms of incompatible code, code that might behave differently, code that might perform differently, features marked for deprecation etc. Some of these things are easy fixes, for instance using the no longer valid syntax for calling RAISERROR. Others require a bit more work, like any old style outer joins using the *= syntax, in this case you will need to re-write the statement but it should be pretty obvious how you need to do that. Still others may need some more involved work, for instance one of our upgrades was using the old version of database mail. The fix for that meant setting up and configuring the target to use the up to date version, and changing every proc to call the new system procedures instead of the old.
As you might be gathering, there can be quite a bit of work involved even with the Data Migration Assistant’s help. But that’s only half the story.
Things the Assistant can’t help with
There are some design patterns you might adopt that make these upgrades harder, because they put code in places the migration assistant can’t see. The obvious example here is dynamic SQL, the migration assistant can’t see the code you will eventually generate because it’s not held directly in any object, and therefore can’t check what obsolete syntax might be lurking.
Similar principals apply to any code held in tables, or held in SSIS packages, or generated in scripts in SSIS packages, or run from the application side, and so on. Basically, any T-SQL code you put anywhere other than directly in a database object will cause you some issues here.
Obviously the first bit of advice I’m going to give you is “don’t do that”. If you keep your code inside your database, limit calls from external sources like SSIS or applications to just executing stored procedures, and resist the urge to write any dynamic SQL, you should be fine. But these things do exist for a reason, and can be useful, and as I’ve written about before, I am actually a fan of dynamic SQL when it’s used properly.
If you do choose to use some of these design patterns, you will do yourself a big favour by keeping the numbers to a minimum, and heavily documenting them somewhere. That way, when you come to upgrade you should have a ready list of trouble spots in your code base, and if you’ve kept them to a manageable number you should be able to check their upgrade compatibility fairly simply.
One way to perform those checks, that we are currently experimenting with, is to just generate stored procedures from those dynamic scripts. Run through the different possible paths (which you should have documented), generate a script for each of them, and wrap them in CREATE PROCEDURE statements. Once you’ve done that, the migration assistant should pick them up the same as anything else. Another option is just to test them thoroughly in your migration test environment. You should ideally have some re-runnable unit and end-to-end tests for this functionality, so do your test migration and run them.
As I said at the start, there’s a lot more to write about SQL Server version upgrades but this post is probably long enough already so I’m leaving it there. Thanks for the prompt, I hope I wasn’t too far off topic.
Today I want to talk a bit about my goals in life, and how I organise them.
Some time ago I cam across the idea of epic life quests. I originally heard about them from Brent Ozar, who had originally heard about them from Steve Kamb, and I liked the idea behind them. I started to work on my own and about 5 years ago I started writing it down. The full list of everything on my quest is here. I realise I’m probably never going to achieve everything on this list, but it helps me keep a certain amount of focus on things that matter to me long-term.
I broke my goals up into various sections, including travel (because I love to travel and have a lot of places I want to see), and hobbies (because it’s important for me to keep doing the things I enjoy and not just working), as well as some work goals.
A couple of years after that, when it was coming close to the end of December, I started to think about what my New Year’s Resolutions would be that year. I was looking at the usual stuff, like lose weight, exercise more, learn something new, when I realised those goals sucked. They weren’t measurable, they never motivated me, they usually couldn’t be broken down into smaller chunks, and largely they were just vague aspirations to be better at some stuff. I decided that year I wasn’t going to do resolutions, I was going to set myself some New Year’s Goals.
I did that, and pulled some of them from my epic life quest and made up a couple more that were just things I needed to get done in the year to stop myself from backsliding, and came up with 6 goals. I hit 3 of them at the end of the year, and although a 50% success rate wasn’t ideal, it was dramatically better than my usual 0% success rate on resolutions. I decided to do that again in the next year, and set myself 10 goals. Unfortunately that was last year, and we all know what a dumpster fire 2020 turned out to be, but I still achieved some of them which was, again, better than nothing.
So, this year I’ve carried that on. So far I’m not doing great but that’s because the New Stars of Data talk happened and interrupted a lot of my planning. I still feel like I’m on course to achieve quite a few of these:
- Tidy up and create some ‘branding’ for my professional presence e.g. this blog, potential talks etc.
- I think the content on this blog is alright, but it could probably use a facelift
- The about me page needs an update, and I need to create a couple more pages as well
- When I update the look of the blog it would be good to update the presentations I give to have a similar look
- Have a painted 40k combat patrol
- One of my nerd hobbies, I’ve always loved the Games Workshop games and now seems like a good time to get back into them as I live just down the road from their HQ.
- Have a painted blood bowl team/underworlds warband
- More Games Workshop stuff
- Blog once a week for 6 months solid
- Last year I did this for 3 months, this year I’m pushing for 6
- Weigh under 95kg every day for 3 months
- Sort out the garden
- Not on my epic quest
- Garden is a state, and I need to properly attack it at some point or I will get in trouble with the letting agency
- Does potentially get me closer to having my ‘garden party’ garden, which is on my quest, but only if I get the full garden party setup before I move
- Earn the Azure Data Engineer certification
- This is almost certainly getting dropped to make room for the New Stars of Data talk
- Finish my novel
- Host a proper Halloween party
- This means everyone dresses up, appropriately spooky decorations and snacks
- Frame and hang all holiday pictures
- I’ve got quite a few paintings etc. from different holidays and I want to get them all framed and hung up around the house
- Not on my epic quest
- Stretch goal if Covid allows – Jordan desert trek
- Not happening this year
- Plan was to trek through the Jordan desert to Petra and the Dead Sea
- New plan is to do a combined Egypt/Jordan holiday next spring when that will hopefully be more practical
- This will tick a few goals off the holiday quests
I came across an interesting quirk of database projects a few days ago. More specifically, a quirk when you come to publish a project that includes check constraints.
I had a few tables with check constraints added to different columns to specify that only particular values could be used in those columns. It looked something like the following:
CREATE TABLE [CheckConstraintExamples].Customer
(
[CustomerID] INT NOT NULL,
[Forename] VARCHAR(50) NOT NULL,
[Surname] VARCHAR(50) NOT NULL,
[Email] VARCHAR(200) NOT NULL,
[CustomerType] VARCHAR(20) NOT NULL,
[CustomerLoyalty] VARCHAR(20) NOT NULL,
[CustomerValue] VARCHAR(20) NOT NULL,
CONSTRAINT [PK_Customer] PRIMARY KEY ([CustomerID]),
CONSTRAINT [CK_Customer_CustomerType] CHECK
(CustomerType IN (
'Basic'
, 'Premium'
, 'Platinum')),
CONSTRAINT [CK_Customer_CustomerLoyalty] CHECK
(CustomerLoyalty IN (
'Low'
, 'Medium'
, 'High'
, 'Lapsed')),
CONSTRAINT [CK_Customer_CustomerValue] CHECK
(CustomerValue IN (
'Low'
, 'Medium'
, 'High'
, 'Superspender'
, 'None'))
);
That all looks ok, and everything published fine, and kept on publishing fine until I happened to check the generated script for some of the publishes (I was in the early stages of development at this point so deployments were just being done through Visual Studio direct to my machine).
When I did I noticed that every deployment I was getting code like this:
GO
PRINT
N'Dropping [CheckConstraintExamples].[CK_Customer_CustomerLoyalty]...';
GO
ALTER TABLE [CheckConstraintExamples].[Customer]
DROP CONSTRAINT [CK_Customer_CustomerLoyalty];
GO
PRINT
N'Dropping [CheckConstraintExamples].[CK_Customer_CustomerType]...';
GO
ALTER TABLE [CheckConstraintExamples].[Customer]
DROP CONSTRAINT [CK_Customer_CustomerType];
GO
PRINT
N'Dropping [CheckConstraintExamples].[CK_Customer_CustomerValue]...';
GO
ALTER TABLE [CheckConstraintExamples].[Customer]
DROP CONSTRAINT [CK_Customer_CustomerValue];
GO
PRINT
N'Creating [CheckConstraintExamples].[CK_Customer_CustomerLoyalty]...';
GO
ALTER TABLE [CheckConstraintExamples].[Customer]
WITH NOCHECK
ADD CONSTRAINT [CK_Customer_CustomerLoyalty]
CHECK (CustomerLoyalty IN (
'Low'
, 'Medium'
, 'High'
, 'Lapsed'));
GO
PRINT
N'Creating [CheckConstraintExamples].[CK_Customer_CustomerType]...';
GO
ALTER TABLE [CheckConstraintExamples].[Customer]
WITH NOCHECK
ADD CONSTRAINT [CK_Customer_CustomerType]
CHECK (CustomerType IN (
'Basic'
, 'Premium'
, 'Platinum'));
GO
PRINT
N'Creating [CheckConstraintExamples].[CK_Customer_CustomerValue]...';
GO
ALTER TABLE [CheckConstraintExamples].[Customer]
WITH NOCHECK
ADD CONSTRAINT [CK_Customer_CustomerValue]
CHECK (CustomerValue IN (
'Low'
, 'Medium'
, 'High'
, 'Superspender'
, 'None'));
GO
PRINT
N'Checking existing data against newly created constraints';
GO
USE [$(DatabaseName)];
GO
ALTER TABLE [CheckConstraintExamples].[Customer]
WITH CHECK
CHECK CONSTRAINT [CK_Customer_CustomerLoyalty];
ALTER TABLE [CheckConstraintExamples].[Customer]
WITH CHECK
CHECK CONSTRAINT [CK_Customer_CustomerType];
ALTER TABLE [CheckConstraintExamples].[Customer]
WITH CHECK
CHECK CONSTRAINT [CK_Customer_CustomerValue];
That’s dropping all my constraints, recreating them using WITH NOCHECK, and then using WITH CHECK to check the existing data. Obviously all the data will pass those checks, but that’s going to add some time to my deployments, and as the size of the data and the number of checks both increase, these checks will take more and more time.
So, what’s going on? The answer was pretty simple really, when you create a table with check constraints like the ones I’ve used, SQL Server doesn’t use the IN when generating the table definition. Instead it breaks that out into a series of OR predicates, and when you deploy again the deployment process doesn’t recognise that the OR predicates are the same as the single IN predicate. Because it thinks the constraints are different, it drops the existing one and creates a new one based on the code in your project. Then the SQL Server engine transforms the IN predicate in the new constraint into a series of OR predicates and the cycle begins again.
The only solution is to re-write the CHECK CONSTRAINTs to use OR instead of IN, like this:
CREATE TABLE [CheckConstraintExamples].Customer
(
[CustomerID] INT NOT NULL,
[Forename] VARCHAR(50) NOT NULL,
[Surname] VARCHAR(50) NOT NULL,
[Email] VARCHAR(200) NOT NULL,
[CustomerType] VARCHAR(20) NOT NULL,
[CustomerLoyalty] VARCHAR(20) NOT NULL,
[CustomerValue] VARCHAR(20) NOT NULL,
CONSTRAINT [PK_Customer] PRIMARY KEY ([CustomerID]),
CONSTRAINT [CK_Customer_CustomerType] CHECK
(
CustomerType ='Basic'
OR CustomerType = 'Premium'
OR CustomerType = 'Platinum'
),
CONSTRAINT [CK_Customer_CustomerLoyalty] CHECK
(
CustomerLoyalty = 'Low'
OR CustomerLoyalty = 'Medium'
OR CustomerLoyalty = 'High'
OR CustomerLoyalty = 'Lapsed'
),
CONSTRAINT [CK_Customer_CustomerValue] CHECK
(
CustomerValue = 'Low'
OR CustomerValue = 'Medium'
OR CustomerValue = 'High'
OR CustomerValue = 'Superspender'
OR CustomerValue = 'None'
)
)
Once I’d done that I thought everything would be fine so I generated another deployment script. Turns out there was one more little thing. When the SQL Server engine generated the object definition for those checks, it ordered the different predicates according to where they were in the original IN predicate, from last to first, which gives definitions like this:
ALTER TABLE [CheckConstraintExamples].[Customer]
WITH CHECK ADD
CONSTRAINT [CK_Customer_CustomerLoyalty] CHECK
((
[CustomerLoyalty]='Lapsed'
OR [CustomerLoyalty]='High'
OR [CustomerLoyalty]='Medium'
OR [CustomerLoyalty]='Low'
))
GO
ALTER TABLE [CheckConstraintExamples].[Customer]
WITH CHECK ADD
CONSTRAINT [CK_Customer_CustomerType] CHECK
((
[CustomerType]='Platinum'
OR [CustomerType]='Premium'
OR [CustomerType]='Basic'
))
GO
ALTER TABLE [CheckConstraintExamples].[Customer]
WITH CHECK ADD
CONSTRAINT [CK_Customer_CustomerValue] CHECK
((
[CustomerValue]='None'
OR [CustomerValue]='Superspender'
OR [CustomerValue]='High'
OR [CustomerValue]='Medium'
OR [CustomerValue]='Low'
))
GO
Whereas if you check my definitions in the previous code block, I’d defined them the other way around. I suspected this meant the deployment engine still thought they were different check constraints, and to test it I deployed my revised project and generated another script. Sure enough, this final script wasn’t dropping and recreating those check constraints any more, and when I regenerated the table definition in management studio, it showed all of the predicates in the order I specified.
I said above that the only way to fix the issue I could see is to re-write the check constraints using a list of OR predicates. That’s not quite true. The other thing you can do is write your constraints like that to begin with, because you’re aware of the issue, and hopefully this blog means a few more of you will do that and not have to go through the re-write task I now have ahead of me.
So, this is pretty cool. Microsoft have brought GREATEST and LEAST functions to SQL Azure, and will be bringing them to on premise versions in a later release (presumably that means the next release).
These work like scalar functions versions of the MIN and MAX aggregations, you write something like GREATEST(1, 3, 4, 2, 6, 7, 5, 9, 13) and it returns the maximum of the values entered (13 in this case). The article gives a few use cases, and there is full documentation for both GREATEST and LEAST in Microsoft Docs.
This is something that’s been wanted for a long time, and in its absence we’ve often resorted to some complicated CASE statements that we’d probably all like to forget, so I’m really happy it’s there in Azure and coming soon to on prem. Now I just have to convince my company that we should probably migrate of SQL 2008 at some point…
Fairly quick one today, just talking about the QUOTENAME() function.
I don’t have the usual aversion to dynamic SQL that you find a lot of developers have. I use it quite regularly as part of my ETL processes, usually to define how data will move from one stage to another. So, for instance, I might have a single Validate procedure that takes a number of parameters, including an import table name, and moves data from that import table to a valid table according to my validation rules. Or I might have a single SCDMerge procedure that takes a transformation view and merges that into a slowly changing dimension (although not using the actual MERGE function for various reasons). These procedures allow me to have confidence that data will always move from one stage to another in the same way, and saves me from writing essentially the same statement 50 times, and having to update it 50 times when I need to change the way we do something, and inevitably missing something and introducing some error.
This always feels like a pretty safe use of dynamic SQL to me, because it avoids some of the more common objections people like to raise to it:
For instance, people will often say that dynamic SQL doesn’t allow re-use of a query plan from the plan cache. This is at least partially true, but for ETL jobs where the query time is measured in minutes, the extra time to generate a plan from scratch every time just stops being an issue.
I also hear that dynamic SQL is hard to troubleshoot. This is true, you have to print out the generated script and run it and look for errors, and then figure out why your actual proc is generating this garbage code with commas all over the place and dangling ANDs in the WHERE clause. But my experience has been that it’s easier to debug this one script than it is to debug 20 different validate scripts for different tables.
Finally, we have the SQL injection risk. This is less of an issue with these scripts as I define a lot of the parameters that get passed in as part of the overall solution. There are some parameters, however, that do get defined externally. For instance, when I import a file, I generate a table with that file’s name and base the columns in that table on the columns in the file. This is still vulnerable to SQL injection if the person sending the file is crafty with a column name somewhere (probably a pretty minor risk as the people sending the files are either from elsewhere in the organisation or clients, but you always need to be careful).
That is where QUOTENAME comes in. This simple function takes any object name and escapes it with square brackets. It also goes through the name and doubles any close square brackets. So something like ‘ColumnName NVARCHAR(MAX)])DROP TABLE dbo.Customer–‘ which might cause some issue if allowed in unsanitised becomes ‘[ColumnName NVARCHAR(MAX) ]])DROP TABLE dbo.Customer– ]’ and therefore creates a column called ‘ColumnName NVARCHAR(MAX)])DROP TABLE dbo.Customer–‘. Now, this might not be exactly what you want but at least it’s not dropping the customer table, and you will probably notice this odd column name and start asking some difficult questions of whoever sent you that file.
Something to note is this only works on valid object names that conform to the SYSNAME data type, i.e. the object name cannot be more than 128 characters. Because of this it returns data as NVARCHAR(258), as that is the maximum length the escaped string could possibly be (if every character is a close square brackets they will be doubled to give 256 characters and the resulting string will be wrapped in square brackets to give a total of 258 characters).
One more thing you can do with this function is specify the escape characters. as a second input (as we have seen, if you don’t do this it defaults to square brackets). So, if you are using double quotes instead of square brackets you would write QUOTENAME(@ObjectName, '"'). This would then wrap @ObjectName in double quotes, and double any double quotes found in the string. This second input only takes a single character, so if you are using any form of brackets it allows you to input either the opening or closing bracket, your choice. So, you could write QUOTENAME(@ObjectName, '>') or QUOTENAME(@ObjectName, '<') and either way you end up with @ObjectName wrapped in angular brackets and any instances of ‘>’ will be set to ‘>>’. There’s a limited number of acceptable inputs for this parameter: single quotes, double quotes, regular brackets (parentheses), square brackets angular brackets, curly brackets, or a backtick (`).
I’m sure there are some other uses for this function beyond dynamic SQL, but that’s the main thing I use it for. I’m currently looking at writing more of my dynamic SQL using C# (at which point I guess it becomes generated SQL instead), and I will need to figure out a C# alternative to QUOTENAME if I’m going to make that work safely.
This is my 8th TSQLTuesday, and this month Steve Jones has invited us to write about Jupyter Notebooks.
I’ve been aware of Notebooks for a little while, but didn’t really know what they were or how to get started with them. Then I attended a talk a few years ago by Rich Benner on Azure Data Studio, which was really interesting in its own right, but also included the ability to create and edit notebooks.
After that I got a bit more interested, and had a bit of a play and did a bit of research. I could see a few use cases for them that other people had written about, things like creating a notebook to pass to the DBAs/admins to run on live and save with the results in as a way to easily do some basic troubleshooting or analysis on a production system
This seemed really appealing at the time, as I was working somewhere where devs were expected to troubleshoot issues on live databases without being able to access them. However, the organisation I was part of moved very slowly and the chances of notebooks or ADS being adopted any time soon was pretty slim so that was, unfortunately, a bit of a non-starter.
Since then I’ve continued to have a play every once in a while, but I’ve never been anywhere where the people around me were much interested, and without that it’s quite hard to get traction with this sort of thing.
I have found one use, however, and that’s as a set of notes for myself.
Recently I was looking to explain to someone about some of the newer syntax that’s available in T-SQL (and when I say newer I mean anything post 2008). I did a quick bit of research and realised there was plenty that I’d forgotten about and didn’t use even when it could be useful for me, so I set up a notebook to very briefly explain the new functionality and include some basic examples. It’s not complete, but you can find it in my GitHub repo.
Going forward I plan on adding a few more notebooks there to help me keep track of any other bits of syntax that I either forget exist or have to research every time I need to use it. I’m thinking one for XML and another for JSON might be really handy, as well as one for all the aggregation/windowing function options. If I can get motivated enough (and that can be a big if) this will hopefully grow into kind of a mini books online, but personalised for me to help me remember the things I need to know.




As mentioned in my last post, I gave my first ever conference talk at New Stars of Data last Friday. Recordings of all of the talks (including mine) are now available on YouTube, and all of the slide decks are available in the NSoD GitHub, or you can find mine here. I’ve not yet been able to listen to mine, but I will manage it someday (my voice always sounds so strange when it’s recorded).
I thought the session went very well, and I had a few nice comments at the end, but I was still more than a little nervous about the feedback form.
As it happens I did pretty well…
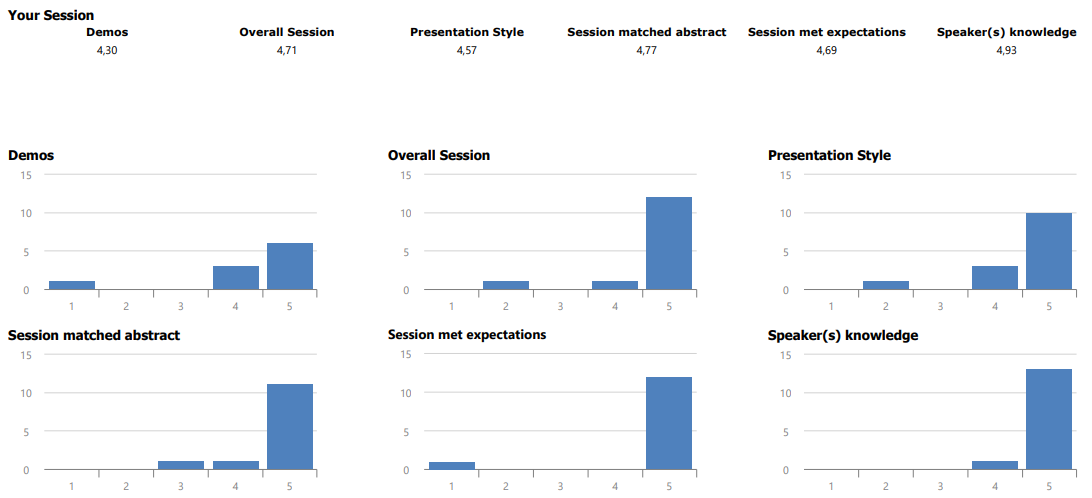
If you can’t see them in the picture, they are:
Demos: 4.3, Overall Session: 4.71, Presentation Style: 4.57, Session Matched Abstract: 4.77, Session Met Expectations: 4.69, and Speaker’s Knowledge: 4.93
I don’t want to brag, but I’m ridiculously happy with these scores. The Speaker’s Knowledge and Overall Session scores in particular just blow me away.
Then, looking at the comments…

Again, really couldn’t be happier.
A few highlights:
This session blew my mind. I did not know that these things are possible with SSDT even though I played with it before. Thank you Chris!
Awesome job Chris! I love it when I can learn new things and you knocked it out of the park. Very well done. You have great pace, tone, & answered questions well. Keep it up and I look forward to more sessions from you.
Excellent session. Interesting topic with clear understanding, clearly expressed.
Feedback
Clearly there’s one person who wanted more demos, and it feels like they wanted in general more of an introduction to Visual Studio database projects. I feel bad for them because I want everyone to get something out of the talk, but it’s not an introduction session. I’m seriously considering putting together an introduction session as a companion to this one, but this session can largely stay as it is. The main thing I might tweak is the abstract, to make it clearer that this is an advanced dive into the topic.
That might seem a bit harsh, but I only have an hour to get everything across. I did want to include some demos in the presentation but that would have meant cutting out 10-15 minutes of talking, which maybe means I don’t get to the really good stuff. Some conferences only have 50 minute slots for speakers so I may need to cut this talk down a bit if I want to try and speak at them in the future (spoiler alert: I definitely do want to try and speak at some of them, speaking was awesome and I very much have the bug now).
How I built the talk in the first place
Part of the reason I know I can’t do everything is because of the way this talk evolved in the first place. I wanted to give a talk at my local user group a couple of years ago, and settled on a general overview of best practices, or things we can learn from the .NET world. This was largely because I’d been working with .NET developers for a few years, and had noticed a lot of ways in which their best practices seemed more embedded than they did in the SQL Server world. I’m talking about things like source control, unit tests, versioning, all kinds of stuff.
Anyway, that first talk was fairly well received even if I was a stuttering mess throughout, and I decided I wanted to do another. This time I figured I’d follow up on what I’d done before and talk in more detail about Visual Studio database projects as an option for source control, as well as a few of the other interesting things you can do with them.
That went a bit better, but I still felt like it wasn’t great. Then I heard about New Stars of Data, and checking the entry requirements I saw that having spoken at a user group before didn’t disqualify you (I guess they were looking for anyone who hadn’t spoken at conference level). I applied with an abstract about what you could do with database projects besides just putting your project under source control, with the aim being to build on the previous talk.
Long story short, I got accepted, and worked really hard with my mentor to try and make a good talk. At the start I figured I’d cut out some of the stuff from the last talk and add a demo, but after Rob saw my slides he said something along the lines of “We have a lot of work to do” and I knew I’d need something a bit more drastic. We ended up with something that looked completely different to the previous presentation, with at least half the content gone, and I needed to cut that. If I hadn’t, if I’d tried to give the introduction talk, I wouldn’t have had the time I needed to really dive into the good stuff that ended up impressing people. As it was, I could definitely have spoken for longer on some of those advanced features, and would love to give the 2-4 hour version that one of the commenters requested! Unfortunately conferences don’t often have slots that long, so I have to pick and choose.
I remain incredibly grateful to the conference organisers, to Rob, to everyone who showed up to listen to me, and to everyone who left feedback. My hope is I can kick on and make this the start of my speaker journey.
